 Loading...
Loading...
Core Competencies Reflection Bio 12
Loading...
 Loading...
Loading...
Loading...
Loading...

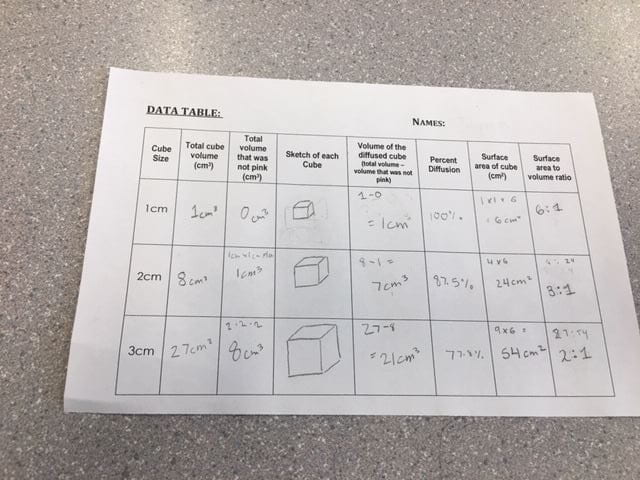
The most effective size cube for maximum diffusion was the small 1cm^3 cube. This was the most effective because, through our results, it diffused through all the way through the cube. It had 100% diffusion
There was a greater ratio between the surface area and the volume of the small cube.
When the surface area becomes larger, the volume also becomes larger causing a smaller diffusion ratio. We calculated to be 6:1 for our 1cm^3 block. This had 100% diffusion. This allowed more of the NaOH To be pulled into the Agar cube. The greater surface area in the membrane and lesser volume allows for more materials to be diffused through the membrane.
In multicellular organisms like plants or animals, there are unique features; gas exchange systems and circulatory. The size is not important within the cells, because if they get too big, they have the ability to divide into efficient diffusers.
DNA and RNA are both types of nucleic acid, holding a central sugar, a phosphate group, and a nitrogenous base, but they do show many differences. mRNA is shorter (about 1000 nucleotides in length) and has one sugar/ phosphate backbone that is straight, unlike DNA’s double helix shape. Instead of deoxyribose sugar that is in DNA, mRNA has ribose sugar in its nucleotides. The Nitrogenous bases are all the same except on RNA, uracil is used instead of Thymine.
The general process of transcription it one Gene of DNA is transcribed onto a strand of mRNA. How this works is first, specific sections of DNA unwinds and unzips at the gene location.

Complementary base pairing occurs with RNA nucleotides in the nucleus creates hydrogen bonds between mRNA bases and DNA bases. The RNA only copies one side of the DNA. Only one side of the DNA contains the genetic code, the other is photo negative. The body makes sure that it is reading the information on the correct side.
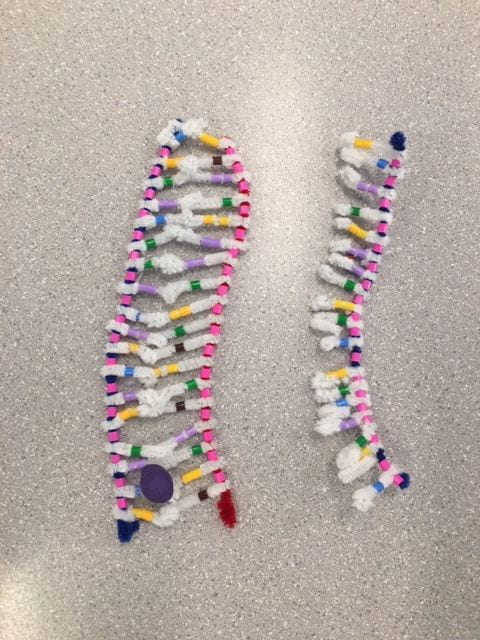
Then the adjacent nucleotides on the RNA form covalent bonds between sugar – phosphates to build the mRNA backbone. All of these steps are facilitated by one enzyme: RNA polymerase. Then the mRNA leaves and the DNA zips back together and twist back into its double helix shape. We need the mRNA to transfer our genetic information because the DNA cannot leave the nucleus of the cell to assemble the proteins, and since the mRNA is shorter and single-stranded, it fits through.

Today’s activity helped me to gain a better understanding of how the mRNA transcribes the message that DNA has in its genetic code. The modeling of the process helped me to visualize the process that takes place. When we unwound the DNA model to transcribe the RNA to it, the DNA was taken apart completely. During the actual process, only specific sections of the DNA get unwound, not the whole thing. The base pairing and creating of Hydrogen bonds worked well and using different color beads to represent uracil used instead of thymine was beneficial to help show the difference in bases, and how it pairs with adenine the same like thymine did. It also helped to use the different color pipe cleaner to represent a different type of sugar backbone being used. Modeling the backbone being created wasn’t an accurate representation because we didn’t have the materials of time to show the separate nucleotides forming hydrogen bonds, not the whole backbone. Each nucleotide attaches separately then forms the backbone. Once the hydrogen bonds are created, then the backbone glues together with the help of RNA polymerase. The DNA is then free to reform its double helix shape, and the mRNA travels trough the pours in the nucleolus to deliver the message to the ribosomes.
Translation is the process in which genetic code on the DNA gets transferred to the ribosomes to make protein. This process takes place in three steps. First is initiation, then elongation, and finally termination.
The translation is the assembly of proteins.
At the start of this process, a “transcription machine” reads the correct strand of DNA to make a copy of its genetic code. This is highlighted more in the questions above, during the transcription process.

Initiation:
Once the mRNA leaves the nucleus of the cell, it travels to a ribosome. The ribosome itself is made of ribosomal RNA and proteins. The mRNA gets read by the ribosome. Within the mRNA are sequences of three-letter words that determine the order in which amino acids occur. These words are called codons and are determined by the order of nitrogen bases. Once the codon AUG passes through the ribosome(red), it signals it to start building amino acid.
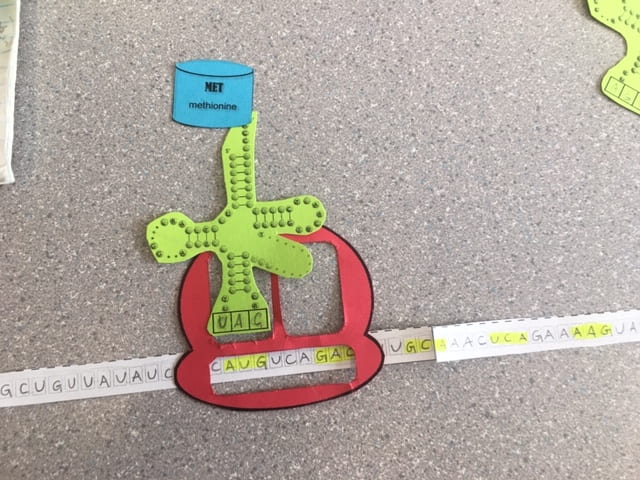
When the ribosome reads this codon, a Transfer RNA (green) attaches to the mRNA in the P docking station in the ribosome. The ribosome contains two docking stations that tRNA can attach to for the RNA to be created. The tRNA has 3 bases that are complementary to the bases on mRNA’s codons. These are called anticodons. At the end of each tRNA is a specific amino acid (blue). AUG is known as the start codon and codes for Methionine. Since AUG starts every chain of amino acid, All proteins begin with a methionine.
Elongation:
The ribosome reads the next codon that is located in the A docking station in the codon. The tRNA with correct anticodon attaches with its specific amino acid.

Once there are 2 tRNA’s on the ribosome, meaning one in each docking station, the amino acid on the tRNA at the P station forms a peptide bond with the amino acid on the tRNA at the A docking station, and the original tRNA that released its amino acid gets let go from the ribosome.

Since the Ribosome doesn’t like to have one tRNA in the A docking station, it gets shifted to occupy the empty P docking station.

The next codon gets scanned and an anticodon tRNA gets called repeating this process.

This process is called elongation because a long string of amino acids gets formed while the ribosome is reading the genetic code on the mRNA

Termination:
The elongation cycle continues to make a chain of amino acids until the mRNA reads a “Stop” codon. A stop codon is a codon that doesn’t have a matching tRNA so no more amino acids can be added to the chain of polypeptides.

The ribosome then dissociates into its two subunits and the polypeptide is released.

After it is released from the ribosome, it is free to form a spiral, pleated sheet, and then fold into its 3D shape which determines the function of the protein.
Today’s activity gave be a good understanding of how mRNA transfers its message to the ribosomes to code for specific proteins and functions. It helped me to understand the difference between mRNA, the RNA that is used to transfer DNA’s message, rRNA – the RNA found in the ribosome, and tRNA, the RNA that is used to transfer the message on the mRNA to a polypeptide. I clearly understood how the ribosome moved throughout the mRNA, and how the tRNA anticodons attached to the codons on mRNA to make the polypeptide, and how it was able to move along to read the rest of the chain. One thing that was inaccurate about this lab was the fact that the ribosome itself is two subunits instead of one. It skipped a step in its translation. Overall this lab helped me to understand the process of protein synthesis.



Because of the specific base pairings, the Strands are in an antiparallel structure. One strand has a Phosphate then sugar order, and the other is sugar-phosphate. The attraction between hydrogen bonds causes it to twist into a double helix shape that we have come to know today.
This Activity helped me to visualize what a strand of DNA looks like, and how the base-pairing worked. Being able to see the sugar-phosphate backbones with the nitrogenous bases perpendicular. It also helped me understand DNA’s antiparallel structure and the bonds between purines and pyrimidines. One thing that I would change to improve the accuracy of the models is to add a different color pipe cleaners to represent hydrogen bonds between bases.
DNA replication is essential for all life and occurs in all living organisms. DNA replicates during cell division before mitosis. It happens during the interphase of the cell cycle when the DNA begins to unwind and unzip for new DNA to be created. This process was first hypothesized in 1953 and is called semi-conservative replication. The Original DNA unwinds and unzips, and each strand pairs with a daughter strand.
Cells may divide when we grow, to repair any damage, and to replace old cells with new healthy ones
Step 1: Unwinding.
 — The DNA unwinds and unzips to break apart hydrogen bonds
— The DNA unwinds and unzips to break apart hydrogen bonds
— This step is facilitated by DNA Helicase which is a wedge-like shape breaking bonds between bases.Step 2: Complimentary base pairing.
— The Nucleotides on the single DNA strands are still attached and the bases want to make hydrogen bonds.
— Free-floating nucleotides in the cell’s nucleus make hydrogen bonds with their complementary base pairs.
— this step is facilitated by the DNA polymerase. The polymerase can only build from 5′ to 3′ meaning is starts on 3′ to the 5′ on the backbone. This causes the leading strand to be built continuously because it is ordered 3′ to 5′.

–The Lagging strand is antiparallel to the leading strand meaning it is built 5′ to 3′. Since the polymerase can only read from 3′ to 5′, the polymerase on the lagging strand has to read backward. This causes the lagging strand to be built in chunks, not continuously.

Step 3 is Joining
— The nucleotides from the new strands of DNA bond together by ligase. Ligase glues together the sugar – phosphates to form covalent bonds between the separate nucleotides. This results in the sugar-phosphate backbone to be formed.

— Finally, the two replicated DNA can twist to form a double helix shape again and begin to function.

We used blue playdoh to demonstrate the DNA polymerase attaching the hydrogen bonds of the complementary bases. One strand was attached all at once in a continuous pattern, where the other was done in fragments. This showed the different ways that the DNA polymerase reads the strands of DNA. The lagging strand is read backward so the polymerase works in fragments to attach the Hydrogen bonds. The leading strand is read forward so the polymerase can read it continuously. The joining step we demonstrated by attaching the red playdoh (ligase) to the backbone of each daughter DNA strand. The ligase is responsible for the covalent bonds in the backbones between the nucleotides. Then the DNA is complete and can form back into a double helix structure. One inaccuracy that we found when demonstrating this is the attachment of the backbone during the Complimentary Base Pairing step. In reality, only the hydrogen bonds between complementary base pairs are present. The backbone of sugar-phosphate is not yet created. That process occurs in the joining step. We couldn’t show the individual bonding between nucleotides because we didn’t have enough material or time to demonstrate it.
Overall, this activity helped me visualize the process of DNA replication and helped me to understand how it works.
Loading...
Loading...
Loading...
Benefits of Social Media Video:
https://sd43bcca-my.sharepoint.com/:v:/g/personal/132-jbettesworth_sd43_bc_ca/ESLEp9nhRc5BsPUSKOt8YasBX_L9flzCR2Gp_82UVT_Kew?e=2UHFGY