Hypothesis
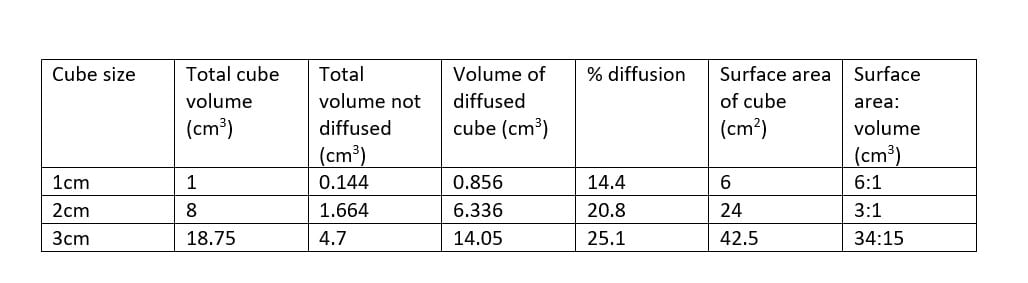
- Smaller the cube is, faster it is diffuse as it has smaller surface area.
In terms of maximizing diffusion, what was the most effective size cube that you tested?
- The 1cm cube was the most effective one.
Why was that size most effective at maximizing diffusion? What are the important factors that affect how materials diffuse into cells or tissues?
- The smaller the size, higher the SA: V ratio. Due to small surface area, it has less surface to cover. Therefore, could have many materials pass through in and out of the “cell” by diffusion.
- Some important factors might be time, size, and possibly temperature.
If a large surface area is helpful to cells, why do cells not grow to be very large?
- Cells would not grow bigger as it would be difficult to transport nutrients to the center and would take longer to regenerate. However, smaller the size, the faster it would be to travel and take lesser time overall.
You have three cubes A, B, and C. They have surface to volume ratios of 3:1, 5:2, and 4:1 respectively. Which of these cubes is going to be the most effective at maximizing diffusion, how do you know this?
- C has the highest surface area to volume ratio. This means that for every cubic unit of cytoplasm, there are more cell membrane than in cubes A and B. This allows for more materials to be able to enter the cytoplasm through diffusion. Therefore, cube C will be most effective at maximizing diffusion.
How does your body adapt surface area to volume ratios to help exchange gases
- Our body adapts the ratio for Alveoli, an air-filled sac inside our lungs. They need a large surface area to volume ratio to allow gas exchange to occur more rapidly in our body.
Why can’t certain cells, like bacteria, get to be the size of a small fish?
- Bacteria are single-celled organisms. As seen in the lab, cells prefer to have a lower volume, so being the size of a fish would not help the functions of the cell. A cell needs to stay small for diffusion of materials.
What are the advantage of large organisms being multi-cellular?
- The advantages are that protein can enter into cells directly, rather then needing the assistance of materials to diffuse into the center of a bigger cell.