
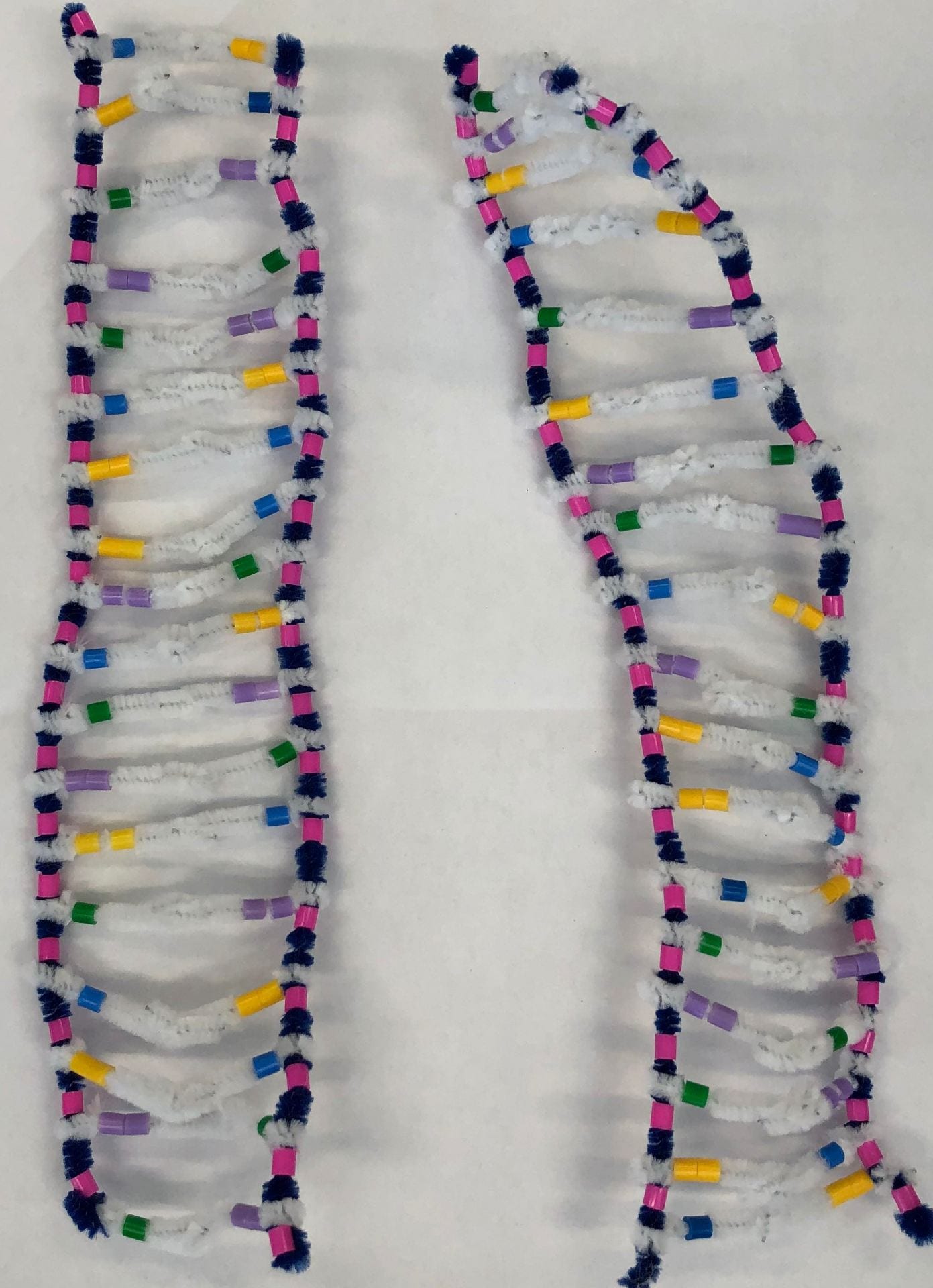
We started our DNA strand with our backbone, its base pairing and nucleotides. (Blue pipe cleaner = 5-carbon sugar backbone, pink beads = phosphates, yellow beads = adenine, blue beads = thymine, purple beads = guanine, green beads = cytosine).

This picture represents the completion of the hydrogen bonding.

The DNA forms a double helix because of the hydrogen bonds.
- Explain the structure of DNA – use the terms nucleotides, antiparallel strands, and complimentary base pairing.
DNA is short for Deoxyribonucleic acid. It is made out of sugars, which is the deoxyribose, nitrogen bases, and phosphates. Essentially, it is a big polymer which is made from nucleotide monomers. It consists of 2 backbones, which are formed by sugar-phosphates from adjacent nucleotides that are bonded. The nucleotide bases face into the ladder and they’e formed by H-bonds that are between the base pairs. The bases are bonded with the same partner every time (Purines with Pyramidines, Adenine with Thymine, and Guanine with Cytosine.). There are two strands in DNA, which are antiparallel strands, where the strands are read from the opposite direction, and complimentary strands, where the strands give the same message.
2. How does this activity help model the structure of DNA? What changes could we make to improve the accuracy of this model?
This activity helps model the structure of DNA by using pipe cleaners and beads to represent different factors in DNA, sugar is represented with blue pipe cleaners, the pink beads represent the phosphates, and the white pipe cleaners represent the hydrogen bonds. It helped with learning the order of the phosphate and hydrogen bonds and painted a clear picture of that. The different colours for the bases showed the bonding pairs for each nucleotide. The accuracy of this model could be changed with more specific measurements, to show how far apart or how close everything should be, such as the distance of the backbones or phosphates.

The DNA helicase untwists and unzips the DNA (Watermelon) and the DNA polymerase (Blue bigfoot) synthesizes the complimentary and base pairs. It works upwards on the strand that begins with phosphate.

The DNA polymerase attaches the complimentary base as DNA ligase (Red bigfoot) and comes and puts the bits together.
The process of replication ends with identical DNA strands.
1. When does DNA replication occur?
DNA replication occurs during cell division. It occurs so that there is DNA present in every new cell and it allows every cell to have the same instructions to create the proteins.
2. Name and describe the 3 steps involved in DNA replication. Why does the process occur differently on the “leading” and the “lagging” strands?
Unwinding and Unzipping, Complementary Base Pairing, and Joining Together of Adjacent Nucleotides. There are enzymes that help the process, DNA Helicase, DNA Polymerase, and DNA Ligase, the three candies in the pictures above. DNA Helicase is the first step, the unwinding and unzipping, it unzips the DNA, and hydrogen bonds are unbonded and the nucleotides are separated. DNA polymerase is the second step, it is when the new nucleotides move in to pair up with the bases of each strand of DNA. The DNA Ligase is the third step, it is when the sugar-phosphate bonds form between the adjacent nucleotides of the new strand which completes the molecule. The new molecule then forms a double helix. The “leading” and “lagging” strands means the polymerase must follow two different ways to add to the nucleotides. The leading is when the polymerase is following the Helicase but the lagging is when the polymerase starts from the top and goes back and forth while the DNA is forming.
3. The model today wasn’t a great fit for the process we were exploring. What did you do to model the complimentary base pairing and joining of adjacent nucleotides steps of DNA replication? In what ways was this activity well suited to showing this process? In what ways was it inaccurate?
The activity was a great way to get a good visual representation of DNA, to really understand how it is formed and replicated. The candies were a good representation in the pictures but it wasn’t really informative because it wasn’t acting with the strands. It was also inaccurate because it wasn’t really clear how the DNA polymerase has to work harder on the lagging strand.

The DNA separates when mRNA is formed.

The strand transcripts in the process that the carbon sugar backbone and the ribose is created with RNA polymerase which attaches to the compliment base.

The mRNA is detached after the transcription.

The DNA reforms and the single RNA strand (Red pipe cleaner) has the instructions and leaves the nucleus.

1. How is mRNA different from DNA?
mRNA is different from DNA because RNA has a 5 – carbon sugar which is called Ribose and DNA has one that is called Deoxyribose. In DNA, Adenine pairs with Thymine but there is no Thymine in RNA so Adenine pairs with Uracil. DNA is a double strand and mRNA is shorter and single stranded which allows it to leave the nucleus.
2. Describe the process of transcription?
The DNA first unwinds and unzips and the leading strand has nucleotides of RNA. Uracil pairs with Adenine because it is part of the RNA and they form hydrogen bonds. RNA polymerase enzyme is what forms this bond and once the strand is created, they separate which leads to the reattachment of DNA and also a backbone of mRNA.
3. How did today’s activity do a good job of modelling the process of RNA transcription? In what ways was our model inaccurate?
The activity which was represented in the mRNA transcription also gave me a good visual of how the DNA copies from the leading strand and how the mRNA is able to leave the nucleus. It was inaccurate because the mRNA strand was not shorter than the DNA strand, we learned that in our notes but it wasn’t anywhere in the instructions or clear with our own DNA strand.
RNA Transcription and Translation
1. Describe the process of translation: initiation, elongation, and termination.
There are three steps for the process of translation. It begins with initiation, this is when the ribosome searches for “AUG” on the mRNA, which is the start codon, this is the two ribosome subunits, the red sheet in the photos. When it finds the codon, the ribosome subunits bind together and reads the mRNA with the AUG in the P site. Simply, this is when the mRNA is held by the ribosome. Next up is elongation, this is when the ribosome brings in the tRNA (green sheet in pics) with the anticodon and that matches the codons on the mRNA. The tRNA also brings in amino acids, which are the little blue sheets in the pictures. As the tRNA binds to the P-Site of the ribosome, another tRNA is able to bind to the codon in the A-Site right next to it, and the amino acid chain starts to grow. When both the sites are full, the amino acid on the P-Site is able to detach itself and attach itself on the amino acid which is on the A-Site. Then the process goes on which a new tRNA being attached to the new exposed codon. The third step is termination, the elongation process continues until the ribosome reads the STOP codon, which is the termination stage. This is simply a codon which does not have a matching tRNA amino acid, so the chain of polypeptides is released and the the ribosome is detached from the mRNA.
How did today’s activity do a good job of modelling the process of translation? In what ways was our model inaccurate?
This was a good way to visually get an idea of all the different stages of translation, they all seemed fairly accurate. I liked that we were able to string the different objects along and got to move the amino acids around on our own. I found that matching up the codons to the anticodons was also very easy with this activity. A few small things were inaccurate about this activity, the RNA was missing the phosphate and sugar strand and it didn’t really demonstrate how the P-Site became the A-Site. Another thing was the accuracy of the shape of amino acids

This is the process of transcription, the RNA Polymerase is transcribing the DNA message to the mRNA.

This represents Initiation, when the ribosome finds the AUG codon and the first tRNA amino acid attaches.

There are amino acids in both the P-Site and A-Site

The amino acid that was on the P-Site transfers to the A-Site and the tRNA is able to exit the P-site.

The ribosome is able to move so that the tRNA is adjusted in the P-Site and not the A-Site anymore.

More steps of Elongation

This is the termination process, when the tRNA in the P-Site gets to the stop codon and there is no amino acid to match it

The Ribosome is released when the tRMA and Amino Acid are detached