
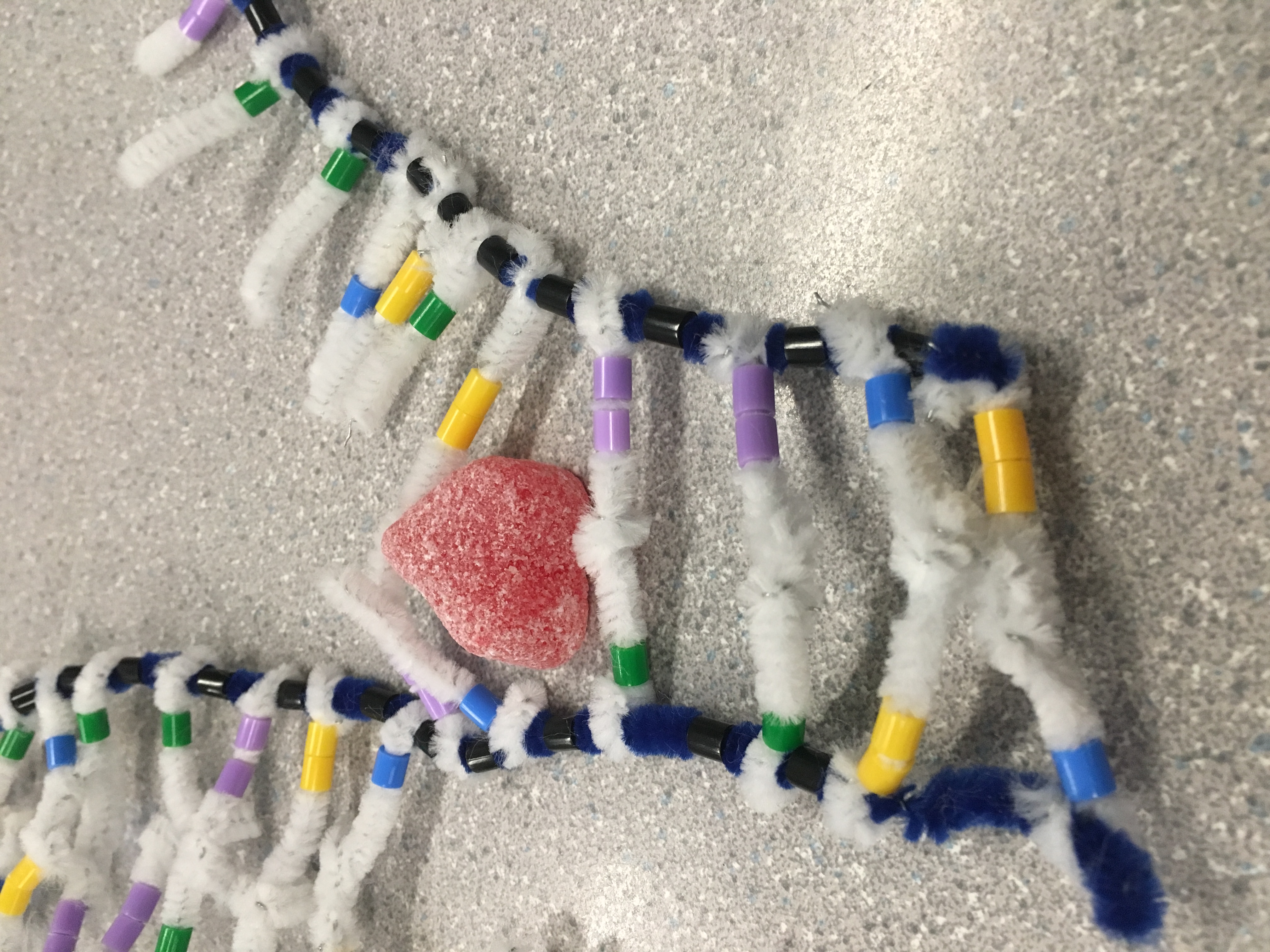
DNA has an alpha helix shape. It consists of nucleotides which are made from pentose, phosphate, and a nitrogenous base. There’s two types of bases: Purines and pyrimidines. Purines have a double ring structure, and contain adenine and guanine. Pyrimidines have a single ring structure, and contain thymine and cytosine. These nucleotides connect with each other to create the double helix shape that DNA has. There is a complimentary base pairing between nucleotides: Adenine bonds with thymine and guanine bonds with cytosine. They are also antiparallel.

It clearly shows how the complimentary base pairs bond together and how the structure of a single nucleotide looks like. After twisting the model, the shape of the DNA is well represented, as the way the DNA twists into a helix is clearly shown. However, the structure of the backbone is a little confusing to understand, from the model. There are beads for phosphates but not for the sugars. If there were also beads for the sugars, it would be easier to show the antiparallel structure of the strands.
Replication
DNA replication begins when the cell recognizes that it’s become too big. It happens just before mitosis, so that the cell can split into two.
The three steps of DNA replication are unwinding, complimentary base pairing, and joining. Unwinding is the first step: The helix untwists, as H-bonds are broken. The helicase enzyme causes these bonds to break.

The next step is complimentary base pairing. Nucleotides pair up with their respective partners: Adenine bonds with thymine, and guanine bonds with cytosine. Polymerase assists with this process.

The final step is joining. A covalent bond between the phosphates and sugars are formed, forming a new strand of DNA. It then twists into the double helix shape. Polymerase reads the DNA strand from 3′ to 5′. The leading strand is the one with the extra sugar at the front. Since polymerase reads DNA in that direction, the lagging strand is read backwards, in sections. The enzyme ligase joins these fragments back together.
Seeing the distinction between each step was made clear with the models. Using different candies to represent the enzymes also showed how each one plays a role within each step. However, it was hard to understand from the model which end was the 3′ end and which was the 5′. The unzipping of the lagging strand was also difficult to clearly model. Since the backbone of the DNA strands were all blue, it is also difficult to show how one strand from the parent DNA gets used to create the daughter strand.

Transcription
mRNA is much, much smaller than DNA. It is one sided and the size of one gene on a DNA strand, allowing it the ability to move in and out of the nucleus. This way, the protein making instructions can be carried out, even though the DNA stays within the nucleus of the cell. DNA has one strand, called the “sense” strand. This contains the instructions for protein synthesis. The other stand, the “nonsense” strand, does not actually contain real instructions, so mRNA must copy the sense strand to carry out transcription.

A strand of information from DNA is copied to a mRNA strand. Like replication, there are three main steps:
- Unwinding
- Complimentary base pairing
- Separation
The DNA untwists with the help of RNA polymerase, which is an enzyme that assists with all three steps. mRNA nucleotides are joined together that are complimentary to the DNA sense strand.

Once copied, the mRNA strand exits the nucleus through nuclear pores and the DNA returns to its original state.

Each of the steps was shown very clearly. With the model, it is easy to visualize what the process looks like, and how it functions. The challenge with this model was showing the mRNA copying the strand of the DNA. The pipe cleaners were unorganized and hard to work with, so this step look confusing. Since our DNA strands were only 1 gene long, the model also does not really show how the size of DNA differs from mRNA.
Translation

In initiation, the ribosome holds the mRNA and reads the first codon (AUG) in the P-site. tRNA has anticodons that are complimentary to the codons on mRNA.

In elongation, the ribosome moves down the mRNA in the 5’ to 3’ direction, and tRNA brings the correct amino acids according to the sequence of codons on the mRNA. The next codon is read in the A – site, and the chain of amino acids in the P – site is transferred to the tRNA in the A – site.

The final step of translation is termination. When the ribosome reads a stop codon (UAG, UGA, UAA), there is no complimentary pair, so the process is ended. The ribosome releases the mRNA, tRNA, and the new protein.
The structure of the ribosome and how it reads mRNA was well represented. With the slot cut out in the ribosome, it was easy to shift the ribosome to the right as it read the codons. The model does not show the release factor and how the polypeptide chain is separated with water.