REPLICATION
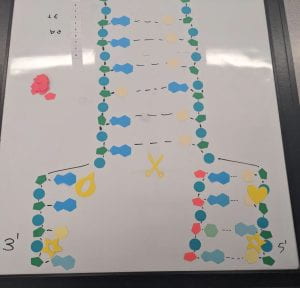

1. Explain the DNA structure – Use the terms nucleotides, antiparallel strands, and complementary base pairing. DNA is a double helix structure formed with two antiparallel strands.
The backbone of a strand is made of phosphate groups and deoxyribose, which are bonded to nucleotides. The other strand’s nucleotides are all the exact opposite variety of the first, which is due to complementary base pairing.
2. When does DNA replication occur?
DNA is constantly replicating because the body constantly needs more amino acids and proteins to grow and replace dying cells.
3. Name and describe the 3 steps involved in DNA replication. Why does this process occur differently on the “leading” and “lagging” strands?
First, the DNA breaks the hydrogen bonds between its nucleotides and separates the two strands. Second, nucleotides are added beside their complementary base pairs on each template strand, and a backbone is added to the new nucleotides. Lastly, the paired strands connect by forming hydrogen bonds between their nucleotides and wind back up into a double helix shape. This process differs between the leading and lagging strands because nucleotides are added to the leading strand starting at the 3′ end, whereas they are added to the lagging strands starting at the 5′ end.
4. Today’s modelling activity was intended to show the steps involved in DNA replication. What did you do to model the complementary base pairing and joining of adjacent nucleotide steps? In what ways was this activity well suited to show this process? In what ways was it inaccurate?
We used different coloured hexagons that represented the different nucleotides to model the complementary base pairing, and we showed the connection between the opposing nucleotides using a dashed line that represented the hydrogen bonds. This activity demonstrated this process well because it allowed us to manipulate and explore the DNA structure, but it was hard to identify the 5′ and 3′ ends because the backbone pieces were not perfectly angled.
TRANSCRIPTION

1. How is mRNA different than DNA?
DNA is a double helix shape with deoxyribose sugar in its backbones and thymine nucleotides. mRNA is a single strand with ribose in its backbone and uracil nucleotides. An mRNA strand is also the conjugate base of a DNA strand and is used to translate proteins, whereas DNA is just a storage of information.
2. Describe the process of transcription.
When a section of DNA unwinds, complementary bases move in to pair with the sense strand and uracil takes the place of thymine in matching with adenosine. The nucleotides form a sugar-phosphate backbone and release from the DNA strand. Then, the DNA rewinds and the RNA can leave the nucleus.
3. How did today’s activity do a good job of modelling the process of RNA transcription? In what ways was our model inaccurate?
I found this modelling activity to be rather counterproductive. I understood all three stages on a theoretical level and the other two models helped me visualize the processes better, but I spent more time trying to assemble this model than actually exploring and understanding it. I did not feel this model aligned well with my previous understanding of the topic.
TRANSLATION
 .
. 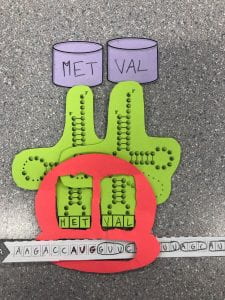

8. Describe the process of translation: Initiation, elongation, and termination.
The process of translation starts when a start codon is found along a strand of mRNA. The anticodon that follows is the first in the polypeptide chain. From there, tRNA containing nucleic acids continue to match with the mRNA codons and elongate the chain. The elongation continues until an end codon is reached along the mRNA strand. There is no anticodon for an end codon, so the rRNA cannot add another nucleic acid and is forced to release the polypeptide chain.
9. How did today’s activity do a good job of modelling the process of translation? In what ways was our model inaccurate?
This model was a good way to visualize how translation works because it requires manually ordering nucleic acids into polypeptide chains. However, in reality, this process goes much faster and hundreds of nucleic acids are processed into a single polypeptide, so the scale of the model was not accurate.









Leave a Reply