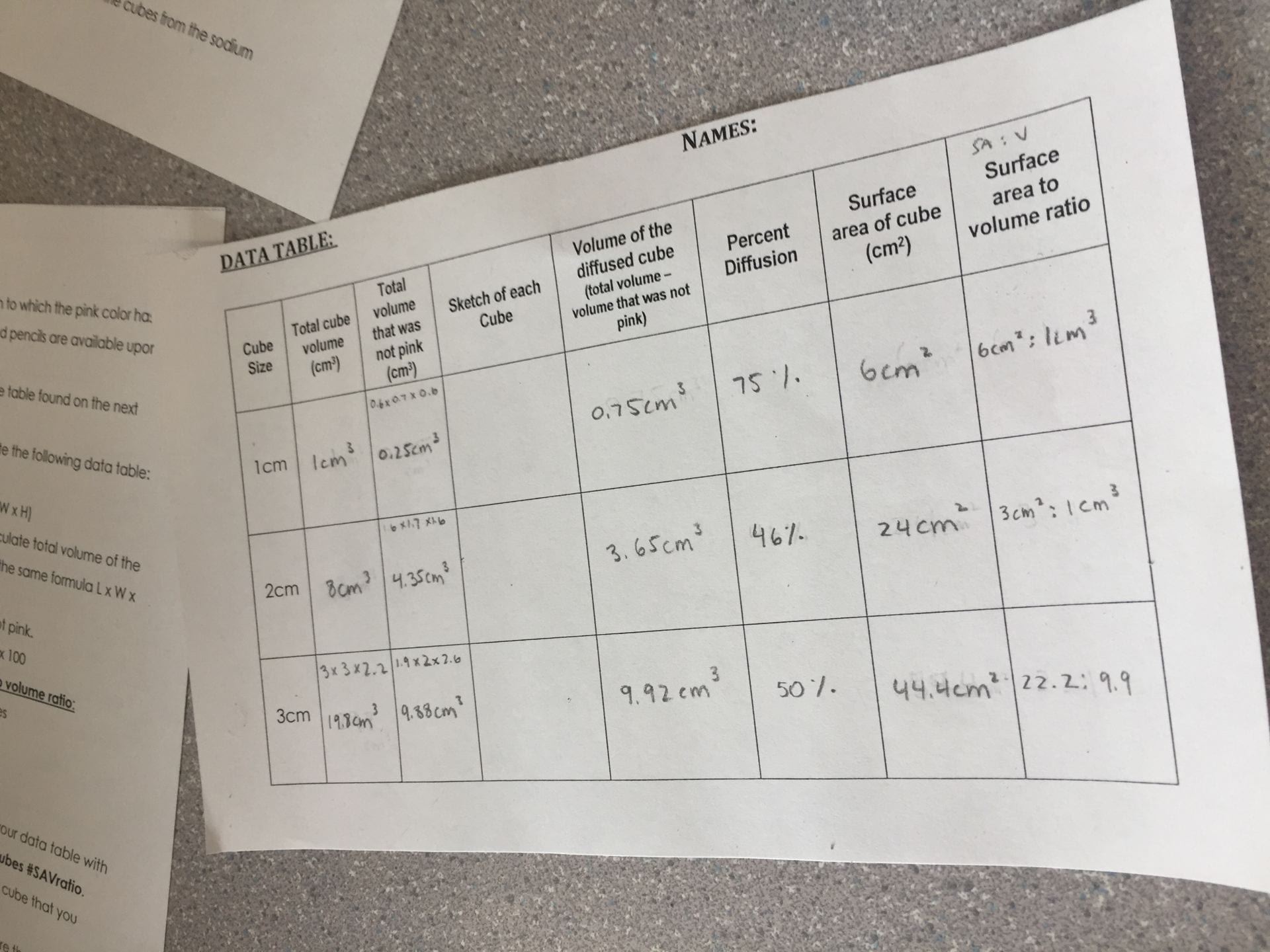
Names: Avery, Hanna, Gracyn, Manroop
Date: April 18th 2019
Introduction:
Glucose is a sugar, which acts as energy for many of the functions our cells do. The glucose level in your body rises when you eat food. This activity will help you learn the relationship between temperature and enzymes, by using lactase enzyme drops. Lactase is an enzyme that works in our bodies to break down the sugar in milk (lactose), but as we grow older our body stops producing this enzyme which is why some people are lactose-intolerant.
In this lab, you will heat four samples of milk to different temperatures and measure the glucose count in each of the test tubes using glucose test strips. Glucose test strips indicate the amount of glucose in a substance by changing colours, each colour represents a different volume in the measurement mmol/L and g/dL.
Purpose: To figure out the effect of temperature on the reaction rate of enzyme reactions.
Hypothesis: Higher temperatures cause a faster reaction rate, therefore more glucose will be present when we test it. Lower temperatures will slow down the reaction rate, therefore less glucose will be present. The test tube heated to above 45 degrees should have no glucose present.
Materials:
- 100 mL milk
- Lactase enzyme drops
- 4 Glucose test strips
- 4 test tubes
- 2 400 mL beakers
- Hot plate
- Ice
- 2 stirring rods
- 2 thermometers
- Test tube rack
- Test tube tongs
- Eyedropper
- Graduated Cylinder
Procedure:
- Measure out 10mL of milk into 4 test tubes
- Put room temperature water (20 degrees Celsius) into one 400mL beaker. Monitor with a thermometer.
- Put cold water (10 degrees Celsius) into the next 400mL beaker. Monitor with a thermometer.
- Put hot water (30 degrees Celsius) into the next 400mL beaker. Monitor with a thermometer.
- Put hotter water (above 45 degrees Celsius) into the last 400mL beaker. Monitor with a thermometer.
- Place one of the milk test tubes into each of the beakers. Place a thermometer in the test tube and watch for the temperature of the milk in the test tube to match the temperature of the water in the beaker.
- Once the test tubes get to the correct temperature, place 2 drops of the enzyme into each test tube and set a timer for 1 minute.
- After one minute, insert a glucose strip into each test tube, take it out, and observe the colour of the strip.
- Match up the colour observed on the strip with the colour on the glucose strip bottle.
| Temperature | Colour of Glucose Test Strip
|
Trace of Glucose
|
| 10°C
|
Teal/Light Green
|
6 mmol/L
|
| 23°C
|
Peanut Brown
|
56 mmol/L
|
| 33°C
|
Dark Brown
|
111+ mmol/L
|
| 65°C
|
Mint Blue
|
0 mmol/L
|
Graph:

Questions:
What did the results show? At what temperature was there the most glucose present – why do you think this was the result?
The glucose strip revealed that the highest glucose count was at 33°C. We believe that this is because as the temperature increases the reaction rate also increases. Whereas, at the lowest temperature, 10°C, there was little glucose present in the test tube.
If the temperature continued to decrease what would happen to the glucose count? Why do you think this occurs?
At 10°C there was the least amount of glucose because the reaction rate is slower at this temperature, which means that we would have to leave the lactase enzyme in the lowest temperature for a longer time in order to get a higher glucose count.
Explain what happened after the enzyme was placed in the test tube above 45 degrees.
Although the glucose count continued to grow as the temperature increased, at the highest temperature, 65°C, no glucose was present in the test tube. This happens because after the lactase enzyme is heated up to a certain temperature the enzyme starts to denature.
Conclusion:
This lab helped us determine the effect of temperature on the reaction rate of enzyme reactions. We predicted that at the lowest temperature the glucose count would be the least and at the highest temperature no glucose would be present. Through this experiment, our hypothesis was proved to be correct. At the lowest temperature little glucose was present because the reaction rate decreases as the temperature lowers. At the highest temperature, 65°C, the glucose strip showed a negative result because the enzyme had denatured. The most glucose resulted in the test tube that was heated to 33°C, this is because enzymes denature at 45° or above, but since this was below that temperature it had the most glucose present. Overall, this lab gave us a clearer understanding of the relationship between temperature and enzymes.
Errors/Improvement:
To improve our lab design, we could’ve tested the lactase enzyme at a variety of temperatures instead of only testing it at four. By doing so, we could get an even greater understanding of the effects of temperature. We think testing one on colder temperatures than what were in our experiment would be interesting. During the lab, it was also difficult to maintain a constant temperature. As well, our timing between dropping in the enzyme and dipping in the strip was not exactly equal between each test tube. For next time, we could be more accurate with this to get a more exact number on the glucose strip.