 Loading...
Loading...
Core Competency Social Justice – Luka Mladenovic
Loading...
Loading...
Loading...

The smallest cube was the most effective when it came to maximizing diffusion.
This cube was the most effective because it had the smallest volume. The smaller the volume of the cube, the solution Has less surface area in which it has to travel. This allows for maximum diffusion. The larger the surface area to volume ratio, the more likely to diffuse at a maximum level it will be.
This suggests that the surface area of the cells must be very large, which would normally result in a large volume. However, a large volume means that more solution has to seep through the cell in order for the cell to be fully diffused. It would suit much better if a cube has a smaller volume. This is because there is less cell to be defused compared to a bigger volume  in which the reaction has to happen at the same rate. It is similar to comparing it to someone running a race. If 1 person is running 100 meters and the other is running 1000 meters, (assuming they are running at the same speed) the one running more distance will require more time to finish the race.
in which the reaction has to happen at the same rate. It is similar to comparing it to someone running a race. If 1 person is running 100 meters and the other is running 1000 meters, (assuming they are running at the same speed) the one running more distance will require more time to finish the race.
Cube C will be most effective at maximizing diffusion because of the larger surface area to volume ratio. The high surface area number means that there is more “space” for the solution to enter the cube, and the low volume number means that there is less internal space within the cube for the solution to fully immerse in. We can see this with the bottom cube in the image, which has turned almost entirely pink as opposed to the top cube which still has a large portion in the center that did not turn pink.
In order for a cell to properly function, there must be a high surface area to volume ratio that allows adequate entering/exiting of gases. This can only happen at certain high SAV ratios, so as the cell grows, the SAV ratio decreases, which results in gas exchange being reduced. Ultimately, the cell loses its ability to function.
As mentioned above, a cell can only properly function when a high SAV ratio is maintained. When a cell is as large as a small fish, the SAV ratio will not be high enough. This will result in the cell undergoing cell division in order to maintain a high SAV ratio. Therefore, bacteria, which are prokaryotes (single-celled organisms) must be small to maintain a high SAV ratio.
Large organisms need their entire body to be composed of cells, and if the organism is unicellular, that will result in a huge cell that has a tremendously low SAV ratio. To eliminate this problem, the organisms are multicellular with tiny cells that lead to higher SAV ratios. Furthermore, these organisms have developed features that allow them to speed up and aid the movement of materials in and out of the organism and the cells. These features include gas exchange organs (our lungs) and our circulatory system (our blood).
Loading...

mRNA is different from DNA in multiple ways. From its structure to its functions, there are numerous differences.
For structural differences, mRNA is single-stranded and short. Where DNA has the classic double helix (Two sugar-phosphate backbones) and has a hefty 85 million nucleotides, mRNA only has one strand (One sugar-phosphate backbone) of about 1000 nucleotides. Finally, mRNA contains a different nucleotide base; where DNA has the base Thymine, RNA has the base Uracil.
For functional differences, DNA has the “blueprint” to create proteins, but mRNA is the method in which DNA’s message gets to the ribosomes. DNA is too large to exit the nucleus, so the smaller mRNA allows the protein synthesis to happen.

During transcription, there are three main steps, and these steps are mostly similar to the ones of DNA Replication. The first step is unwinding/unzipping. Here, the helix unwinds into the ladder form and then unzips.


The next step of RNA transcription is complimentary base pairing. A sugar-phosphate backbone containing the sugar Ribose and not the sugar Deoxyribose comes in to create the complimentary strand of one DNA backbone strand (shown as blue pipe-cleaner). It will have the same complimentary bases with one exception: instead of the base Thymine, mRNA will have the base Uracil. The mRNA (shown as the red pipe-cleaner) will create a complimentary strand of the leading strand only because this strand contains the essential information on how to build proteins. The enzyme RNA Polymerase will facilitate this process, creating H-bonds between the nucleotides and bonding the backbone and the nucleotides. While this is happening, the lagging strand of DNA in not involved. This is modelled in the image below.

The final step is called separation. This happens when the RNA Polymerase is finished transcribing DNA’s message onto the mRNA, and the mRNA will simply float away. The DNA leading and lagging strands will rejoin and reform the double helix, whereas the mRNA will be checked for any errors in the base sequence. There, it will be modified so that all the bases are correct, and unnecessary bases will be taken away. mRNA can now exit the nucleus towards the ribosomes and DNA is in its original double helix with nothing changed to it.

Our activity was able to clearly demonstrate how the process of Transcription works. The diagrams nicely show how each step looks, and gives us a nice visual representation. There were, however, a couple of ways the model could have been different so that the process is better depicted. One way was that the strand of DNA was equal in length to the strand of mRNA, so it was difficult to show the process of the double helix unzipping at regions where the transcription occurs. Consequentially, we had to depict the process of unzipping as a full “unzip” and not just a partial “unzip”.
Before translation occurs, transcription must first be completed. RNA Polymerase will complete the transcription of DNA’s message onto mRNA. This will allow the ribosomes to read this message.

The first process is called initiation. This is when the transcribed mRNA approaches the ribosome. The ribosome has two sites: the P-site in the left, and the A-site in the right. The mRNA base sequence is divided into groups of three bases called codons. These codons will translate into a certain amino acid. The mRNA will “look” for the codon AUG – this is the “Start Codon”. This codon will enter the P-site, and the next codon will be in the A-site. A tRNA will enter the P-site.
tRNA is a special type of RNA that has a specific anti-codon. Every tRNA will have one specific anti-codon, and also carries the amino acid it corresponds to. For example, when the ribosome reads the codon AUG, it will call for the tRNA with the anti-codon UAC that carries the amino acid Methionine.

The next process is called elongation. This is when the amino acids brought in by the tRNA begin to create a polypeptide. Once the codon in the P-site is read, the codon in the A-site will also be read. From there, the tRNA carrying the right amino acid will enter the ribosome. Now, both sites are filled, so the amino acid in the P-site will bond with the amino acid in the A-site.

Now, the tRNA in the P-site has no amino acid, which allows it to leave. Due to the P-site being empty, the mRNA will shift to the left; this puts the tRNA with the two amino acids in the P-site, and the A-site empty for a new amino acid to enter. This process continues, creating a long chain of amino acids.

The final step of translation is called termination. There are certain codons that will not correspond to an amino acid due to there not being a tRNA with the proper anti-codon. This is a message to the ribosome to stop adding amino acids to the polypeptide chain. There are three variations of these codons that stop the elongation process, which are fittingly named “Stop Codons”. In this case, the ribosome will let go of the mRNA and will let go of the amino acid polypeptide. The protein that was intended by DNA’s message is now completely created and ready to function.
This model of translation is quite accurate to the actual process of translation. It provided a nice visual representation of how the process occurs, which also made it easier to understand. One way that we could improve this model could maybe be by making the amino acids something more block-y and 3-D. The flat paper made it difficult to envision the primary structure that would soon twist and turn into the globular form of a tertiary/quaternary structure protein.
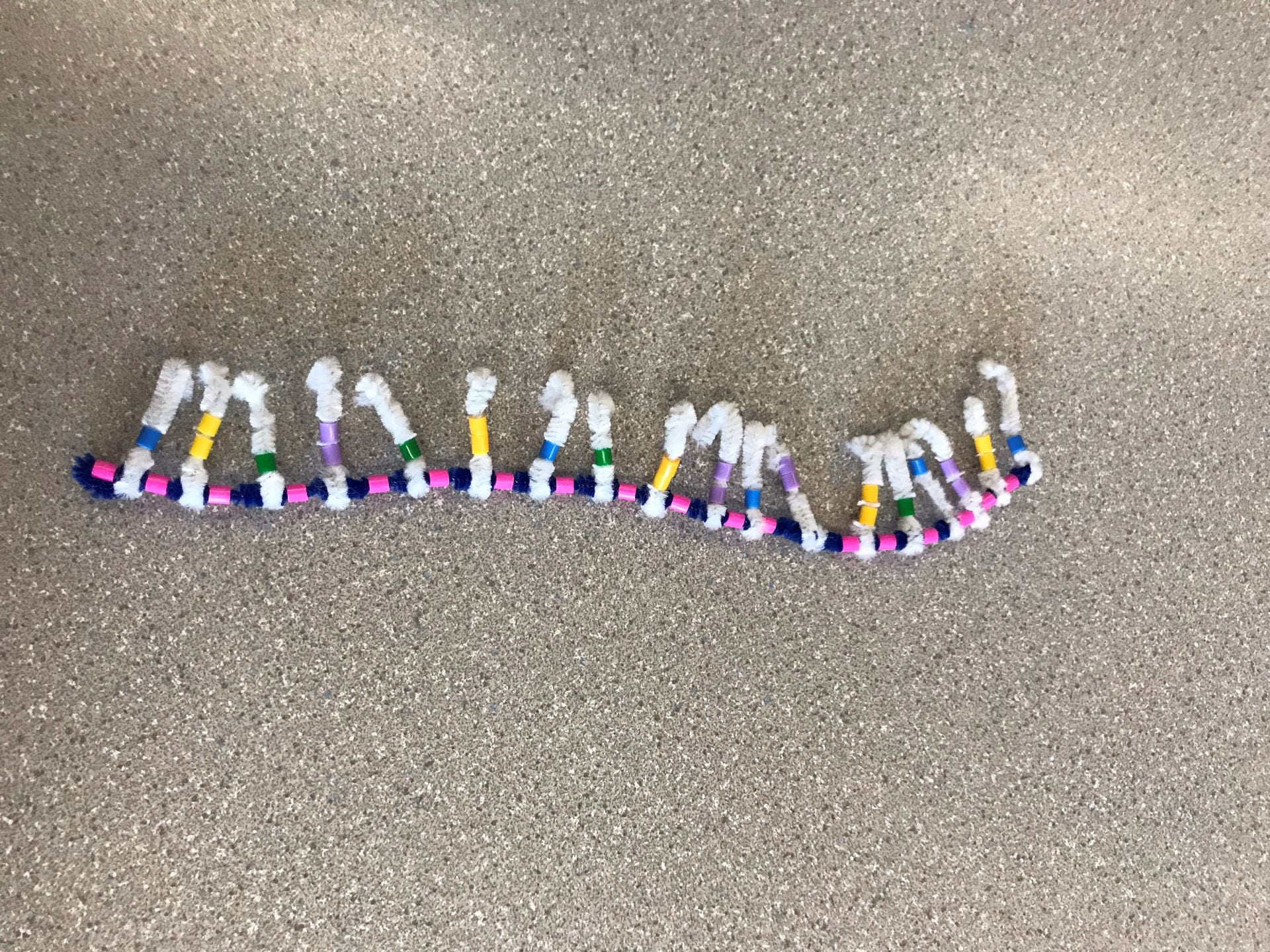
DNA is created by having two backbones of sugar-phosphate groups, as we can see with the blue pipe cleaner (the Deoxyribose sugar) and the pink beads (the phosphate groups). The order must always go in an alternating order of sugar-phosphate or vice versa. Each sugar-phosphate group has a nitrogen-containing group sticking out. The group of sugar-phosphate-base is the basic monomer for DNA which is called a nucleotide. Many nucleotides are bonded together to form a strand of DNA.
There are four different bases: Adenine (Yellow bead), Guanine (Purple bead), Cytosine (Green bead), Thymine (Blue bead). Adenine and Guanine are purines, which mean they have two rings. This is represented by Adenine and Guanine having two beads. Cytosine and Thymine are pyrimidines, which mean they have one ring. This is represented by Cytosine and Thymine having one bead. The bases follow a “protocol” called complimentary base pairing, which means that a certain base will only bond with another certain base. Adenine (A) will only bond with Thymine (T), and Guanine (G) will only bond with Cytosine (C).
The first strand will start with three specific bases, and this is the same for all strands of DNA. The sequence goes T, A, C. This means that the opposite strand will begin with the sequence A, T, G. From there, the sequence will differ for different strands of DNA, and there will be complimentary base pairing for the opposite strand.

When the strand is completed, the opposite, complimentary strand will be created following two different “rules”. The first is that the sugar-phosphate groups will be facing the opposite way. This means that if the first, original strand had a sequence of sugar-phosphate, the opposite strand will have a sequence of phosphate-sugar. This is called an antiparallel strand. The second is that the bases will be complimentary to the first strand following the complimentary base pairing rule. This means that the complimentary strand will begin with the three bases A, T, G. The bases in the two strands will H-bond with one another, creating a form that looks similar to a ladder.

Now that the ladder form is complete, the strand must twist into a double helix. DNA molecules have a right-handed twist and is twisted evenly throughout. The form of DNA that most people know is now complete.
The model of DNA and its characteristics are very well demonstrated by this activity. The diagram is almost identical to what the textbook models suggest. In the textbook diagrams, it is hard to see that the backbone is made of a sugar-phosphate group since it just looks like a backbone strand. The activity could be more accurate by putting the bases closer to one another, farther from the sugar-phosphate backbone. The last suggestion for this activity would be twisting the strand into a more accurate double helix. The pipe cleaners and the beads were prone to falling apart if they were twisted too much. If there was a certain way to allow the strand to twist more without breaking, that would be better.
Cells, much like ourselves, age and become defunct. In that case, the cells must reproduce via cell division. However, the DNA in the parent cell nucleus must also be copied into the new cell nucleus. This happens via DNA replication. DNA must be copied and remade into a new strand of the same DNA before any cell division can occur. Therefore, DNA replication occurs when cell division happens.

There are three steps during DNA replication.
The first step is called the unwinding, or the unzipping process. In this step, the double helix untwists itself back into the ladder form and is unwounded/unzipped. This unzipping is facilitated by an enzyme called DNA Helicase, which breaks the H-bonds between nitrogen-containing bases so that the ladder is separated into the two separate backbones.

The second step is called Complimentary Base Pairing. This is the process where the unzipped strands begin to find their new “partner” strands. Nucleotides of all types are floating around in the nucleus. Complimentary bases to the original strand are brought in and connected into fragments. This process is facilitated by the enzyme DNA Polymerase. The direction in which DNA Polymerase reads and strand and brings in complimentary bases is strictly one-way; from Carbon-3 to Carbon-5 to be exact. For the leading strand, the sequence of the backbone molecules goes 5 to 3, which means that it follows a phosphate-sugar sequence. This means that as the DNA unravels, the DNA Polymerase can continue to read the strand and bring in complimentary bases. For the lagging strand, it is the opposite. The sequence of the backbone molecules goes 3 to 5 (sugar-phosphate sequence). This means that as the DNA unravels, the DNA Polymerase reads the strand in the same direction as the strand, which means that the DNA Polymerase has to return to the beginning of the unravelling Replication Fork and read again.

The final step is called joining. This is the process where fragments of complementary bases are “glued” together into a long backbone strand. This is facilitated by the enzyme DNA Ligase. From there, once the long strand of complementary bases are completed, they form H-bonds with their complementary bases of the original strand. Now, the original strand has successfully formed two new DNA strands with two separate backbones. They will twist again and form a double helix.
It was difficult to show the individual nucleotides floating towards the replication site since we had not thought of cutting up the blue pipe cleaner to demonstrate this. Due to this, we had modeled the process of Complimentary Base Pairing and Joining virtually together. Furthermore, we did not have the best idea as to where the DNA Ligase should have been, so after looking at various diagrams on Google, we decided to simply put the Ligase near the fragment of complementary bases. This would have been an inaccurate way of showing this model. Also, for the unravelling of the DNA, we were not entirely sure if the TAC sequence of the leading strand had to be the first to unravel, or the last to unravel. We ended up guessing that it would be the beginning that unravels first, and we’re still not sure whether that is the case or not.
However, there were many accurate representations in the model that we made. For example, the DNA Helicase looked mostly like the pictures of DNA Helicase that we saw in the notes or in textbooks. The general model looked like the diagrams in the notes as well. The way that we had shown the H-bond between the bases (hooking the white pipe cleaners together) made it relatively simple for us to unhook the “bond” and separate them to show the process of Complementary Base Pairing.
Loading...
There are 3 types of nerve cells. Represented here is the Interneuron.

The photo below is a photo of the Structure of a Synapse along with its parts labeled.
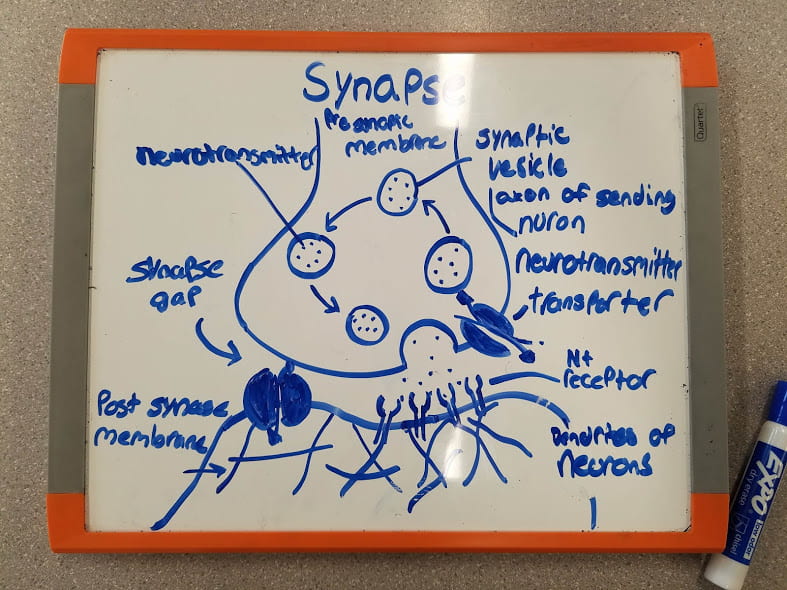
Synapse Function
How a signal is sent from the axon of sending neuron to the dendrite of receiving neuron
How the receiving neuron “determines whether or not to send its own action potential.











